When dealing with analysis and interpretation of data, it is very important to identify errors related to analysis to obtain clear conclusion.
The common errors related to Null Hypothesis are Type I and Type II errors.
Type I error or Alpha (A): This occurs when we are rejecting a true null hypothesis. It can be easily remembered as A -- R. A can refer to true null hypothesis.
Type II error or Beta (B): This occurs when we are accepting a wrong null hypothesis. It can be easily remembered as B -- A. B can refer to wrong null hypothesis.
As a step to reduce both errors simultaneously, the sample size should be increased to obtain clearer picture about the scenario. When the data tends to follow normal distribution clearly, the errors are reduced.
Another step is to increase the reliability or credibility of the data that is studied to prevent the occurrence of the errors.
From Beta, we can calculate the power of the test. That Power of test = 1 - B.
Tuesday, November 9, 2010
Friday, June 11, 2010
The Concept of Probability
The mathematical theory of probability was discovered by two Frenchmen: Blaise Pascal and Pierre Fermat. Although gambling was the first to play a major role in the applications of probability, the subject has evaded the entire universe. In recent times, almost everything is described in terms of probabilities.
As we find that day-to-day life is full of uncertainities, there arises a critical need to measure these uncertainities to reach a certain point. Probability can be described as the science of measuring uncertainities. It is a numerical representation of an abstract situation.
The three main methods adopted to measure probability of the occurance of an event are:
1) Relative frequency approach:
The frequency of the event is divided by the sample size.
2) Subjective or intuitive approach:
When required data about the event is unavailable, the probability is measured completely on previous experience, belief or intuition.
3) Classical approach:
The number of outcomes favourable to the event is divided by the total number of outcomes.
Facts of probability:
1) The probability of an event A is denoted by P(A).
2) The value always lies between 0 (0% chance) and 1 (100% chance).
3) The sum of probabilites of related events in an experiment is always 1.
Note: The sum of probabilities of occurance & non-occurance of an event is also 1. Let p & q be the probabilities of occurance & non-occurance of an event. Then p+ q = 1. This implies q = 1 - p.
Let us consider a few examples:
1. Kris told Joe the probability of her car starting tomorrow morning is just about 0.
a) What method did Kris use for assigning this probability to the event that her car will start?
b) If Kris is correct and the probability of her car starting is close to 0, would you say the car is likely to start or not? What would you say if the probability were close to 1?
Ans: a) Kris has used the subjective or intuitive method to assign the probability.
b) As 0 represents no occurance of the event, it is very clear that the car is not likely to start. As 1 represents 100% occurance of the event, with probability 1, it can be said that the car will definitely start.
2. The city council has three liberal members (one of whom is the mayor) and two conservative members. One member is selected at random to testify in Washington, D.C.
a) What is the probability this member is liberal?
b) What is the probability this member is conservative?
c) What is the probability the mayor is chosen?
Ans: Based on the data, the Classical method would be the best.
a) P (member is liberal) = 3/5
b) P (member is conservative) = 2/5
c) P (mayor) = 1/5.
As we find that day-to-day life is full of uncertainities, there arises a critical need to measure these uncertainities to reach a certain point. Probability can be described as the science of measuring uncertainities. It is a numerical representation of an abstract situation.
The three main methods adopted to measure probability of the occurance of an event are:
1) Relative frequency approach:
The frequency of the event is divided by the sample size.
2) Subjective or intuitive approach:
When required data about the event is unavailable, the probability is measured completely on previous experience, belief or intuition.
3) Classical approach:
The number of outcomes favourable to the event is divided by the total number of outcomes.
Facts of probability:
1) The probability of an event A is denoted by P(A).
2) The value always lies between 0 (0% chance) and 1 (100% chance).
3) The sum of probabilites of related events in an experiment is always 1.
Note: The sum of probabilities of occurance & non-occurance of an event is also 1. Let p & q be the probabilities of occurance & non-occurance of an event. Then p+ q = 1. This implies q = 1 - p.
Let us consider a few examples:
1. Kris told Joe the probability of her car starting tomorrow morning is just about 0.
a) What method did Kris use for assigning this probability to the event that her car will start?
b) If Kris is correct and the probability of her car starting is close to 0, would you say the car is likely to start or not? What would you say if the probability were close to 1?
Ans: a) Kris has used the subjective or intuitive method to assign the probability.
b) As 0 represents no occurance of the event, it is very clear that the car is not likely to start. As 1 represents 100% occurance of the event, with probability 1, it can be said that the car will definitely start.
2. The city council has three liberal members (one of whom is the mayor) and two conservative members. One member is selected at random to testify in Washington, D.C.
a) What is the probability this member is liberal?
b) What is the probability this member is conservative?
c) What is the probability the mayor is chosen?
Ans: Based on the data, the Classical method would be the best.
a) P (member is liberal) = 3/5
b) P (member is conservative) = 2/5
c) P (mayor) = 1/5.
Saturday, May 29, 2010
Correlation
While understanding the behaviour of the variables, measuring the relationship between the variables also becomes crucial. The coefficient explains the strength of the relationship between any two or more variables.
Correlation is simplest tool used to measure the relationship. It is actually the covariance of standardized variables. Or it is the average of standardized covariance.
Assumptions
Based on the type of variables, there are different types of correlation methods:
1. Pearson's r Correlation: Interval vs Interval
2. Spearman's Rho: Ordinal vs Ordinal or Interval vs Ordinal
3. Polyserial Correlation: Interval vs Ordinal (when the distribution between the interval variable and a latent continuous variable underlying the ordinal variable is bivariate normal)
4. Polychoric Correlation: Ordinal vs Ordinal (when the distribution between the two latent continuous variables underlying the two ordinal variables is bivariate normal)
5. Biserial Correlation: Interval vs Dichotomous with bivariate normality assumption. This can be greater than 1.
6. Point Biserial Correlation: Interval vs Dichotomous
7. Rank Biserial Correlation: Ordinal vs Dichotomous with bivariate normality assumption
Chi-Square Test is used to test the bivariate normality. If p<0.05, there is bivariate normality.
The table below is a pictorial representation

Correlation is simplest tool used to measure the relationship. It is actually the covariance of standardized variables. Or it is the average of standardized covariance.
Assumptions
a. Linearity of data
b. Homoscedasticity – equal error variance at any point along the linear relationship
c. No outliers – A large difference between r and rho is a sign of its presence.
d. Measurement error reduces systematic covariance and hence lowers r leading to attenuation.
e. Unrestricted variance in the variables.
f. Similar distributions (type) of the variables
g. Normality of variables and errors.
Based on the type of variables, there are different types of correlation methods:
1. Pearson's r Correlation: Interval vs Interval
2. Spearman's Rho: Ordinal vs Ordinal or Interval vs Ordinal
3. Polyserial Correlation: Interval vs Ordinal (when the distribution between the interval variable and a latent continuous variable underlying the ordinal variable is bivariate normal)
4. Polychoric Correlation: Ordinal vs Ordinal (when the distribution between the two latent continuous variables underlying the two ordinal variables is bivariate normal)
5. Biserial Correlation: Interval vs Dichotomous with bivariate normality assumption. This can be greater than 1.
6. Point Biserial Correlation: Interval vs Dichotomous
7. Rank Biserial Correlation: Ordinal vs Dichotomous with bivariate normality assumption
Chi-Square Test is used to test the bivariate normality. If p<0.05, there is bivariate normality.
The table below is a pictorial representation

Tuesday, May 25, 2010
Measures of central tendency - Suitable application
The measure of central tendency is a single value that represents the whole set of observations. Given below is 5 measures of central tendency and their suitable application in real-life.
1) Mean - It is the average of all the observations. It is applicable to continuous data following normal distribution, i.e. the outliers or extreme values in the data set do not affect the average significantly.
Eg: Average score of a class of students, average height of a group of members.
2) Median - It is the middle most observation in the data set when it is arranged in ascending order. That is, the measure is based on position. It is applicable to continuous and discrete data not following normal distibution. That is, when there are outliers that can affect the centralization, the median is observed. It can be mostly related to revenue.
Eg: Average income of a group of associates, Average turnover of a company.
3) Mode - It is the value that occurs most number of times in the data set. It is applicable to discrete or continuous data concerning frequency or common occurance. In some cases, the data set may have two modes or no mode.
Eg: Movie with average popularity (measured from the number of tickets sold), average earthquake measurement in an area,
4) Geometric mean - It is the nth root of the product of n values. The geometric mean of two numbers, 6 and 8 is the square root of (6x8 = 48). It is used in the case of observations related to time.
Eg: Average rate of return in investment in a year is calculated by taking the root of the product of each year's rate of return.
5) Harmonic mean: It is the reciprocal of the arithmetic mean obtained from taking the values in reciprocal form. It is used when the values of a variable depend on other factors or determinants. That is, this measure is used to harmonize the values and then find their mean.
Eg:
a) Calculating the average speed on a car in a distance of 40 kms. from four different readings as:
100 km/hr in the first 10 kms
90 km/hr in the second 10 kms
110 km/hr in the third 10 kms
105 km/hr in the final 10 kms
b) Calculating the average score of a student based on the scores in written test and interview. This helps to eliminate two types of students
i) who score well in written test but score poorly in interview
ii) who score poorly in written test but score well in interview.
1) Mean - It is the average of all the observations. It is applicable to continuous data following normal distribution, i.e. the outliers or extreme values in the data set do not affect the average significantly.
Eg: Average score of a class of students, average height of a group of members.
2) Median - It is the middle most observation in the data set when it is arranged in ascending order. That is, the measure is based on position. It is applicable to continuous and discrete data not following normal distibution. That is, when there are outliers that can affect the centralization, the median is observed. It can be mostly related to revenue.
Eg: Average income of a group of associates, Average turnover of a company.
3) Mode - It is the value that occurs most number of times in the data set. It is applicable to discrete or continuous data concerning frequency or common occurance. In some cases, the data set may have two modes or no mode.
Eg: Movie with average popularity (measured from the number of tickets sold), average earthquake measurement in an area,
4) Geometric mean - It is the nth root of the product of n values. The geometric mean of two numbers, 6 and 8 is the square root of (6x8 = 48). It is used in the case of observations related to time.
Eg: Average rate of return in investment in a year is calculated by taking the root of the product of each year's rate of return.
5) Harmonic mean: It is the reciprocal of the arithmetic mean obtained from taking the values in reciprocal form. It is used when the values of a variable depend on other factors or determinants. That is, this measure is used to harmonize the values and then find their mean.
Eg:
a) Calculating the average speed on a car in a distance of 40 kms. from four different readings as:
100 km/hr in the first 10 kms
90 km/hr in the second 10 kms
110 km/hr in the third 10 kms
105 km/hr in the final 10 kms
b) Calculating the average score of a student based on the scores in written test and interview. This helps to eliminate two types of students
i) who score well in written test but score poorly in interview
ii) who score poorly in written test but score well in interview.
Friday, May 21, 2010
Test to measure relationship between variables
Based on the scale of the variables, different statistical methods are available to determine the relationship or association between the variables. Suitable graphs also provide more clarity on the relationship.
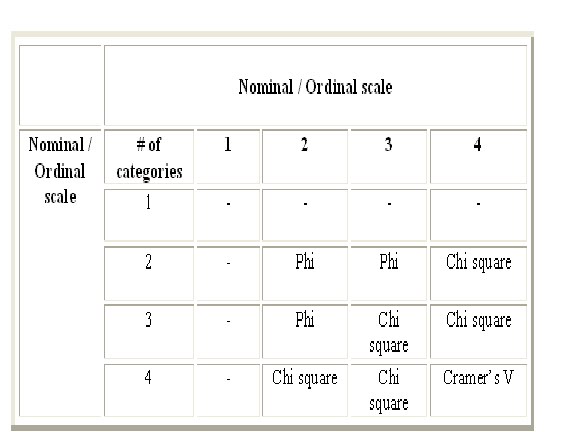
Nominal vs Nominal:
Chi-square, Phi, Cramer 's V (Clustered Bar graph)
Nominal vs Ordinal :
Chi-square, Phi (2X2, 2X3, 3X2 tables), Cramer's V (> 3X3 table) (Clustered Bar graph)
Nominal vs Interval / Ratio :
Point bi-serial correlation (Scatter plot, Bar chart)
Ordinal vs Ordinal :
Spearman's Rho, Kendall's Tau (Scatter Plot, Clustered Bar Graph)
Ordinal vs Interval / Ratio :
Spearman's Rho, Kendall's Tau, Point bi-serial correlation (Scatter Plot)
Interval/Ratio vs Interval/Ratio :
Pearson r (Scatter Plot)
Nominal vs Nominal:
Chi-square, Phi, Cramer 's V (Clustered Bar graph)
Nominal vs Ordinal :
Chi-square, Phi (2X2, 2X3, 3X2 tables), Cramer's V (> 3X3 table) (Clustered Bar graph)
Nominal vs Interval / Ratio :
Point bi-serial correlation (Scatter plot, Bar chart)
Ordinal vs Ordinal :
Spearman's Rho, Kendall's Tau (Scatter Plot, Clustered Bar Graph)
Ordinal vs Interval / Ratio :
Spearman's Rho, Kendall's Tau, Point bi-serial correlation (Scatter Plot)
Interval/Ratio vs Interval/Ratio :
Pearson r (Scatter Plot)
Wednesday, May 19, 2010
Understanding Level of Measurement
Level of Measurement: It provides a classification used to describe the nature of the information contained within the variable. The classification level of the variable will determine the types of calculations that can be performed using the variable.
Nominal Scale: The level of measurement involving numeric or alphanumeric responses which can be grouped. But the groups are distint and cannot be compared. Eg. Red, Green, Yellow, Male, Female
Ordinal Scale: The level of measurement involving numeric or alphanumeric responses which can be grouped. But the groups can be arranged in an order. In other words, the distance between the numeric responses is fixed but meaningless. Eg. Rating, Ranking
Interval Scale: The level of measurement involving numeric responses with decimal point. In other words, the distance between the responses is not fixed but meaningful. Eg. Temperature.
Ratio Scale: The level of measurement involving numeric responses with absolute zero. In other words, the responses represent intervals but are not expressed below the zero value. Eg. Height, Weight, Coverage value in Market Research.
Nominal Scale: The level of measurement involving numeric or alphanumeric responses which can be grouped. But the groups are distint and cannot be compared. Eg. Red, Green, Yellow, Male, Female
Ordinal Scale: The level of measurement involving numeric or alphanumeric responses which can be grouped. But the groups can be arranged in an order. In other words, the distance between the numeric responses is fixed but meaningless. Eg. Rating, Ranking
Interval Scale: The level of measurement involving numeric responses with decimal point. In other words, the distance between the responses is not fixed but meaningful. Eg. Temperature.
Ratio Scale: The level of measurement involving numeric responses with absolute zero. In other words, the responses represent intervals but are not expressed below the zero value. Eg. Height, Weight, Coverage value in Market Research.
Understanding Variables - clarity on data
To understand the variable type is very much important in all the statistical analysis. Given below is the classification table on the statistical variables.

Variables:
Quantitative variables: Variables containing numerical responses. Eg. Temperature, Age, Monthly Income etc.
Description
Variables:
Quantitative variables: Variables containing numerical responses. Eg. Temperature, Age, Monthly Income etc.
Qualitative variables: Variables containing numerice or alphanumeric responses. Based on the responses, the data can be categorised. Hence it is also called as Categorical variable. Eg. Gender, Employee id, Department, Favorite colour etc.
Continuous variables: Variables containing numeric responses with decimal point. Eg. Temperature, Marks, Cost of products etc.
Discrete variables: Variables containing numeric responses as integers i.e. without decimal point. Eg. Age, Number of defects, Number of products purchased or sold.
Subscribe to:
Comments (Atom)